

Incremental Data Processing: The Patterns Behind Fast, Reliable Pipelines
Process only what changed. Not everything, every time.

Every data pipeline starts the same way: a query that pulls the whole table, transforms it, and writes it back out. It works great for about a month. Then the table crosses a few million rows, the nightly job that used to take ten minutes starts taking two hours, and your warehouse bill quietly doubles.
The fix is almost never “make the full reload faster.” but It’s “stop doing a full reload.” Incremental processing means designing your pipeline so each run only touches the data that’s new or has changed since the last run, also called the delta instead of the whole dataset.
That sounds simple, but it raises real questions:
how do you know what changed? What do you do with deletes?
What happens if a record arrives late, or your job crashes halfway through?
This post walks through the core conceptual patterns: watermarks, change data capture, merge/upsert strategies, and idempotency.
Why Incremental Processing Exists
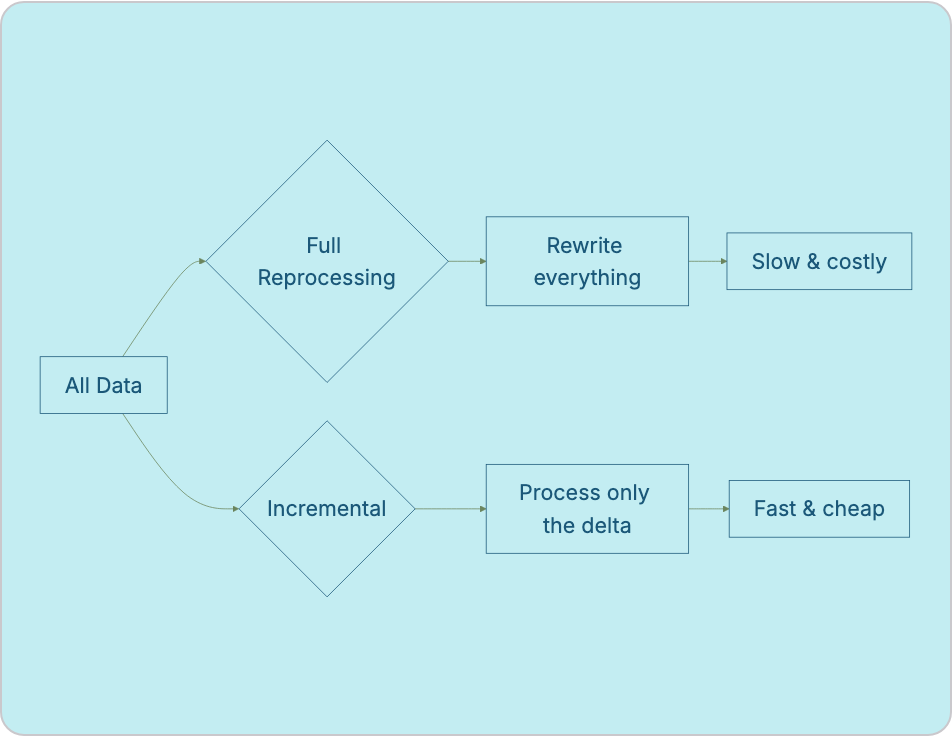
A full reprocessing pipeline re-reads and rewrites the entire dataset on every run. It’s conceptually simple, there’s no state to track, and the output is always a clean, complete rebuild. But the cost scales with the total size of your data, not the size of the change. As tables grow, full reloads get slower and more expensive in lockstep, even on days where almost nothing changed.
Incremental processing addresses this by isolating the new or changed records and processes only those. The cost scales with the rate of change, not the total volume. which is why it is the default approach for any dataset that’s grown past “small enough to just rebuild.”
The trade-off is complexity. Incremental pipelines need to answer:
what is new since last time?
what do I do with it once I have it?
The rest of this post covers both halves of that question.
Change Data Capture (CDC)
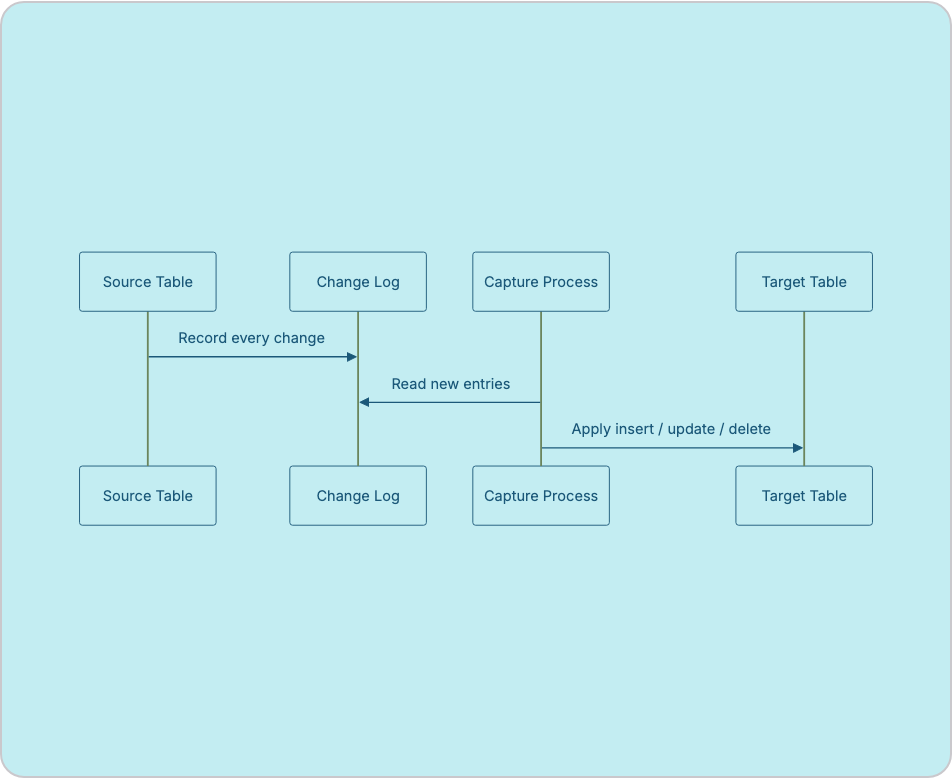
CDC process reads the database’s own change log: an ordered, append-only record of every write the database has made (majority of database engines that supports transactions keeps one of these internally for crash recovery and replication). A capture process tails this log and turns each entry into a discrete change event.An insert, an update, or a delete which downstream consumers apply to a target table in the same order they happened.
When to use
Sources where deletes matter. financial records, inventory, anything where this row disappeared is meaningful information.
Systems that need a complete history of changes, not just the current state
Low-latency pipelines, since the log can be tailed continuously rather than polled on a schedule. Tool used: debezium
The Watermark Pattern
The watermark pattern is the simplest way to answer “what is new?”.
You keep track of a high-water mark: the value of some monotonically increasing column (usually a timestamp like updated_at, or an incrementing ID) representing the last record you successfully processed.
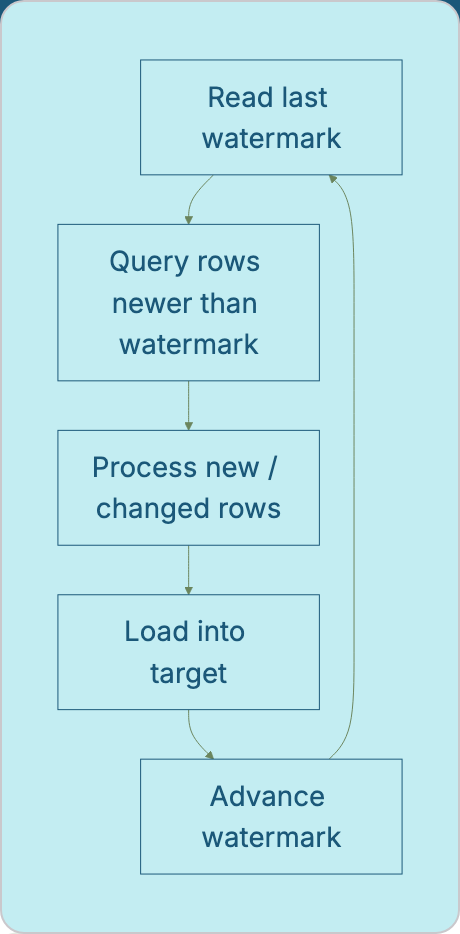
Each run:
Reads the stored watermark
Queries the source for rows the newer records based on the watermark
Processes those rows
Advances the watermark to the new maximum value after the load succeeds
When to use
Data sources with a reliable, indexed last updated/created timestamp or sequential ID
Append-heavy data (logs, events) where rows are rarely modified after creation
Quick wins, it requires no special infrastructure beyond a small state table
Merge & Upsert Strategies
Once you know what’s new (via a watermark, CDC, or anything else), you still need to decide how to apply the changes to the target table. There are three conceptual approaches, and the right one depends entirely on how your records behave over time.
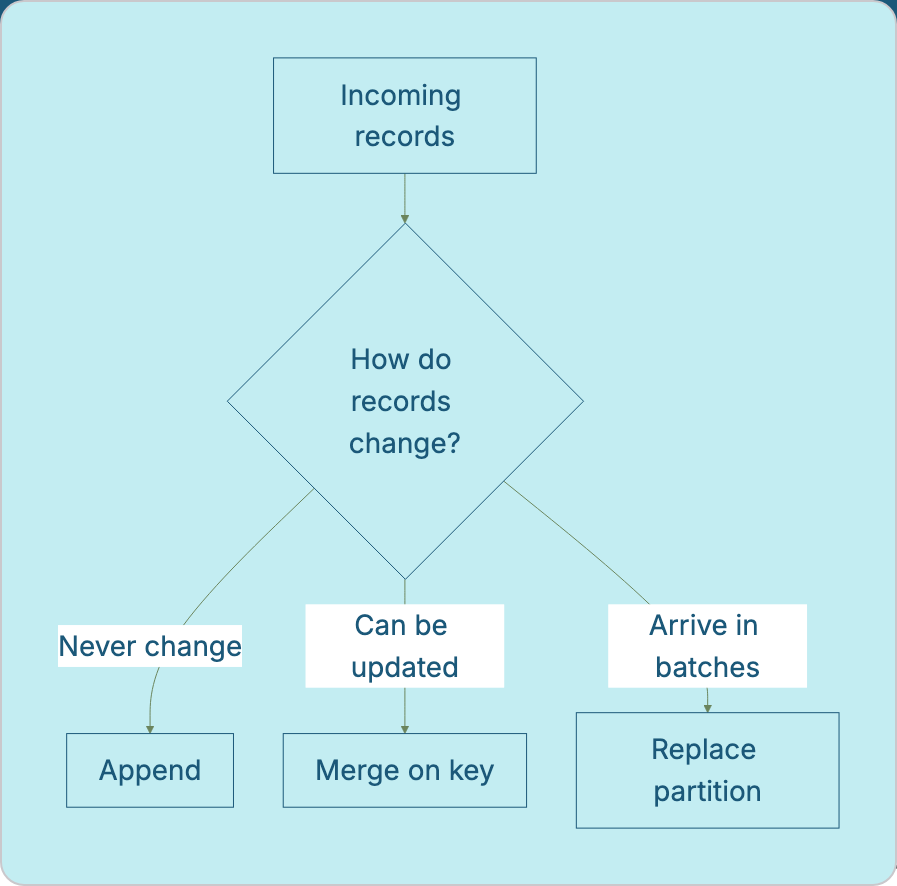
Append
If a record is immutable once written, for instance a clickstream event, a log line, a sensor reading there there is nothing to update. You just add the new rows to the end of the target table. This is the cheapest possible strategy: no scanning for existing rows, no matching logic. The risk is that re-running the same batch twice produces duplicates so it only works safely when paired with a watermark (or similar guard) that prevents reprocessing the same range twice.
Merge / Upsert
If records can be updated after creation an order whose status changes, a customer profile that gets edited, you need to match incoming rows against existing ones by a unique key, updating matches and inserting everything else. This is the most common pattern for fact and dimension tables. The cost is that the database has to find matching keys, which gets more expensive as the target table grows though the incoming batch is still small, which is the whole point of incremental processing.
Replace-Partition
If your data arrives in time-bounded batches a day’s worth of transactions, an hourly export then it is often simplest to throw away and rebuild one well-defined chunk at a time, rather than matching individual rows. This sidesteps row-level matching entirely and makes re-running a batch trivially safe. Re-running it just replaces the same partition again. It only works cleanly when your data has a natural partitioning key (like a date) and corrections always arrive scoped to a full partition.
Idempotency & Late-Arriving Data
The patterns above answer the changes and how to apply changes to the target table. Production pipelines also have to survive failures and stragglers.
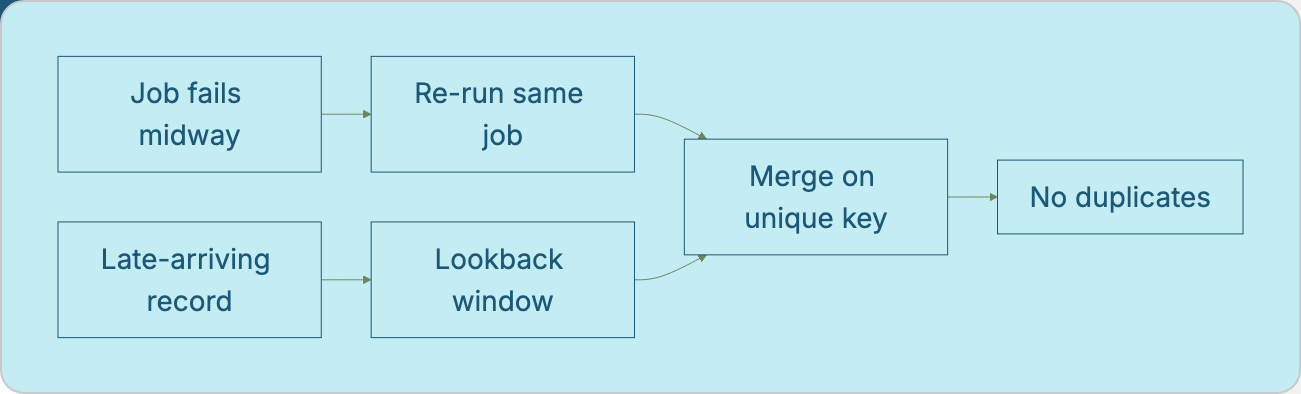
Idempotent retries
A pipeline is idempotent if every run with same input produces the same result as running it once. This matters because jobs will fail partway through and when they do, the safest recovery is usually run it again.
Append is only idempotent if you can guarantee the same batch never gets re-submitted (e.g., the watermark genuinely didn’t advance on failure).
Merge on a unique key is naturally idempotent as applying the same upsert twice leaves the table in the same state both times.
Replace-partition is idempotent by construction as it just overwrites the same partition with the same data on re-run.
When in doubt, prefer merge or replace-partition over plain append for anything that touches a target table directly. I have primarily worked with these types of pipelines throughout the use cases I have handled.
Lookback windows
Watermarks assume data arrives in order but real systems have clock skew, retries, and out-of-order delivery. A record with updated_at = 09:58 AM might not actually land in your source table until 10:05 AM, after your pipeline already advanced its watermark past 10:00.
A lookback window fixes this by deliberately re-scanning a small slice of recently-processed data on every run, not just the strictly-new range:
SELECT * FROM source WHERE updated_at > (:last_watermark - INTERVAL ‘1 hour’);Combined with a merge-on-key apply step, this is safe: records that were already processed get matched and updated (or re-written identically), and the late arrival finally gets picked up typically within one run after it actually lands.
Choosing the Right Pattern
Full reload
Sees deletes: Yes (trivially)
Operational complexity: Low
Best fit: Small tables, simple pipelines, infrequent runs
Watermark extraction
Sees deletes: No
Operational complexity: Low
Best fit: Append-heavy sources with a reliable “updated at” column
Change data capture
Sees deletes: Yes
Operational complexity: High
Best fit: Mission-critical sources where deletes and full history matter
Merge / upsert apply
Sees deletes: Depends on source
Operational complexity: Medium
Best fit: Mutable fact/dimension tables, regardless of how the delta was identified
Replace-partition apply
Sees deletes: N/A (replaces whole chunk)
Operational complexity: Medium
Best fit: Time-partitioned batch data with occasional corrections
In practice, these aren’t mutually exclusive. A typical production pipeline picks one technique to identify the delta (watermark or CDC) and one to apply it (merge, append, or replace-partition), then layers idempotency and a lookback window on top for safety.